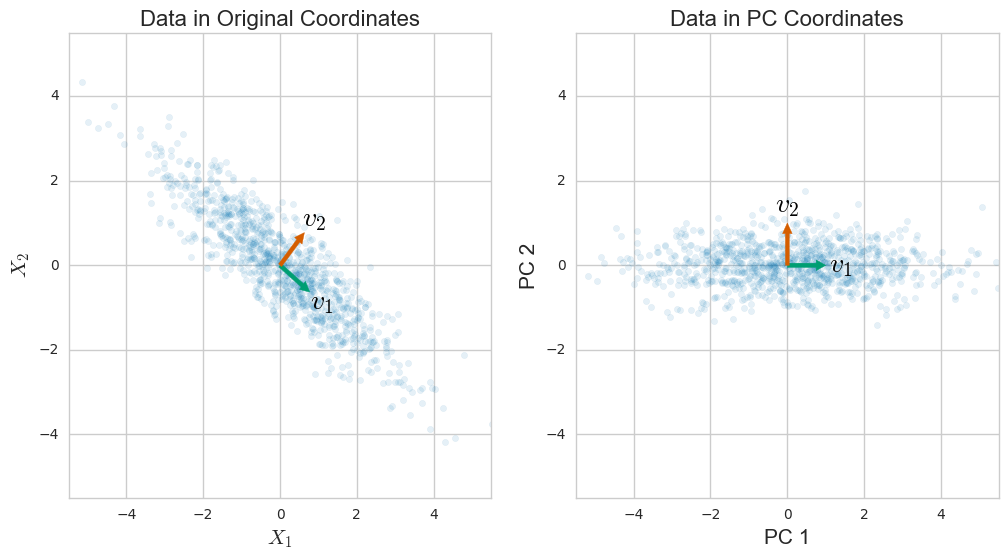
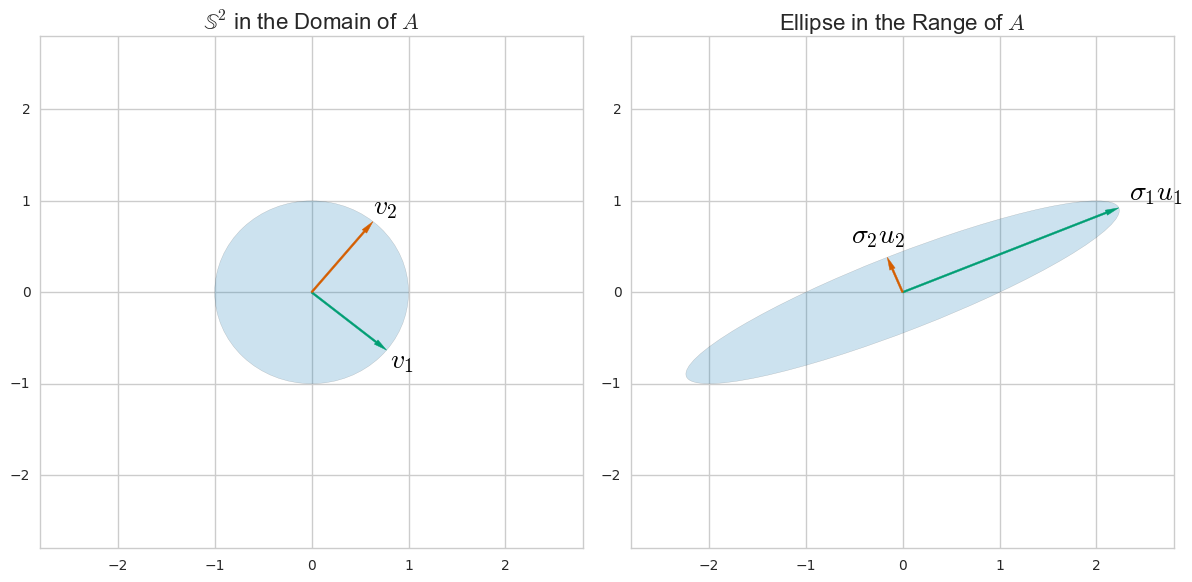
ප්රධාන සංරචක විශ්ලේෂණය (පීසීඒ) සාමාන්යයෙන් විස්තර කරනු ලබන්නේ සහසංයුජ අනුකෘතියේ අයිජන්-වියෝජනයෙනි. කෙසේ වෙතත්, දත්ත න්යාසයේ ඒකීය අගය වියෝජනය (SVD) හරහා ද එය සිදු කළ හැකිය . එය ක්රියාත්මක වන්නේ කෙසේද? මෙම ප්රවේශයන් දෙක අතර ඇති සම්බන්ධය කුමක්ද? SVD සහ PCA අතර සම්බන්ධතාවය කුමක්ද?
නැතහොත් වෙනත් වචන වලින් කිවහොත්, මානයන් අඩු කිරීම සිදු කිරීම සඳහා දත්ත අනුකෘතියේ SVD භාවිතා කරන්නේ කෙසේද?
8
මම නිතර අසන පැන විලාසිතාවේ ප්රශ්නය මගේම පිළිතුරක් සමඟ ලියා තැබුවෙමි, මන්ද එය නිතර නිතර විවිධ ස්වරූපයෙන් අසනු ලබන නමුත් කැනොනිකල් නූල් නොමැති බැවින් අනුපිටපත් වැසීම දුෂ්කර ය. කරුණාකර මෙටා ත්රෙඩ් එකේ මෙටා අදහස් දක්වන්න .
—
amoeba
පීසීඒ තවත් SVD මත පදනම් වූ ශිල්පීය ක්රම කිහිපයක් ලෙස සලකනු ලබන මෙහි වැඩිදුර සබැඳි සහිත විශිෂ්ට හා සවිස්තරාත්මක ඇමීබා පිළිතුරට අමතරව මෙය පරීක්ෂා කිරීමට මම නිර්දේශ කරමි . එහි සාකච්ඡා තෑගි වීජ ගණිතය පාහේ පමණක් සුළු වෙනසක් සමග amoeba ගේ සමාන එහි කතාව, පීසීඒ විස්තර වන්නේ, svd විසංයෝජනය ගැන ගිය [හෝX/ √ ] වෙනුවට X- සහසංයුජ අනුකෘතියේ eigendecomposition හරහා සිදු කරන ලද PCA හා සම්බන්ධ වන බැවින් එය පහසුය.
—
ttnphns
PCA යනු SVD හි විශේෂ අවස්ථාවකි. PCA සඳහා දත්ත සාමාන්යකරණය කළ, එකම ඒකකයක් අවශ්ය වේ. PCA හි අනුකෘතිය nxn වේ.
—
ඕර්වර් කෝර්වර්
R ඕර්වර්කෝර්වර්: ඔබ කතා කරන්නේ කුමන nxn න්යාසය ගැනද?
—
Cbhihe